Introduction to Neural Networks: How They Work and Why They Matter

Table of Contents
“Neural networks power today’s smartest systems, transforming raw data into predictions, insights, and intelligent automation across vision, language, and decision-making.”
Introduction
Neural networks power almost everything exciting in AI today — from ChatGPT-style language models and image generators like Midjourney, to voice assistants, self-driving cars, medical diagnostics, fraud detection, and personalized recommendations on Netflix or Jumia.
But what exactly are they? How do they actually learn? And why have they become the backbone of modern artificial intelligence?
This beginner-friendly guide explains neural networks from the ground up — no heavy math required. We'll cover what they are, how they're built, how they learn, and why they matter so much in 2026.
What Is a Neural Network?
A neural network (or artificial neural network — ANN) is a computational model loosely inspired by the human brain. It consists of thousands (or millions) of simple processing units called neurons (or nodes) organized into layers.
These neurons work together to:
- Take input data (e.g., pixels of a photo, words in a sentence, sensor readings)
- Transform it through layers of calculations
- Produce an output (e.g., "this is a cat", "translate to Yoruba", "approve loan", "predict stock price")
Unlike traditional rule-based programming ("if pixel is dark here → it's an edge"), neural networks learn patterns directly from data — no hand-written rules needed.
Basic Structure of a Neural Network
Most neural networks follow this layered architecture:
-
Input Layer
Receives raw data.
Example: For a 28×28 pixel handwritten digit image (MNIST), there are 784 input neurons (one per pixel). -
Hidden Layers (the "magic" happens here)
One or more layers that transform the data.
Each neuron in a hidden layer:- Takes inputs from the previous layer
- Multiplies each by a weight
- Adds a bias
- Applies an activation function (introduces non-linearity)
- Passes the result forward
-
Output Layer
Produces the final prediction.
Example: For digit recognition (0–9), 10 output neurons — the highest value wins.
| Layer Type | Purpose | Typical Neurons (example) |
|---|---|---|
| Input | Receives raw data | 784 (image 28×28) |
| Hidden (1+) | Learns complex patterns | 128, 256, 512... |
| Output | Gives prediction/classification | 10 (digits), 1 (regression) |
How Do Neurons Work? (The Math — Simplified)
Each neuron performs this basic operation: output = activation_function( (input1 × weight1) + (input2 × weight2) + ... + bias ) text- Weights → importance of each input (learned during training)
- Bias → offset (shifts the decision boundary)
- Activation Function → decides if/ how strongly the neuron "fires"
Popular activation functions (2026 standards):
| Function | Formula | Best For | Why Used? |
|---|---|---|---|
| ReLU | max(0, x) | Hidden layers | Fast, avoids vanishing gradients |
| Sigmoid | 1 / (1 + e^(-x)) | Binary output (0–1) | Old-school, outputs probabilities |
| Tanh | (e^x - e^(-x)) / (e^x + e^(-x)) | Hidden layers (older nets) | Zero-centered, better than sigmoid |
| Softmax | exp(x_i) / Σ exp(x) | Multi-class output | Turns scores into probabilities |
Rectified Linear Unit (ReLU) dominates today because it's simple and effective.
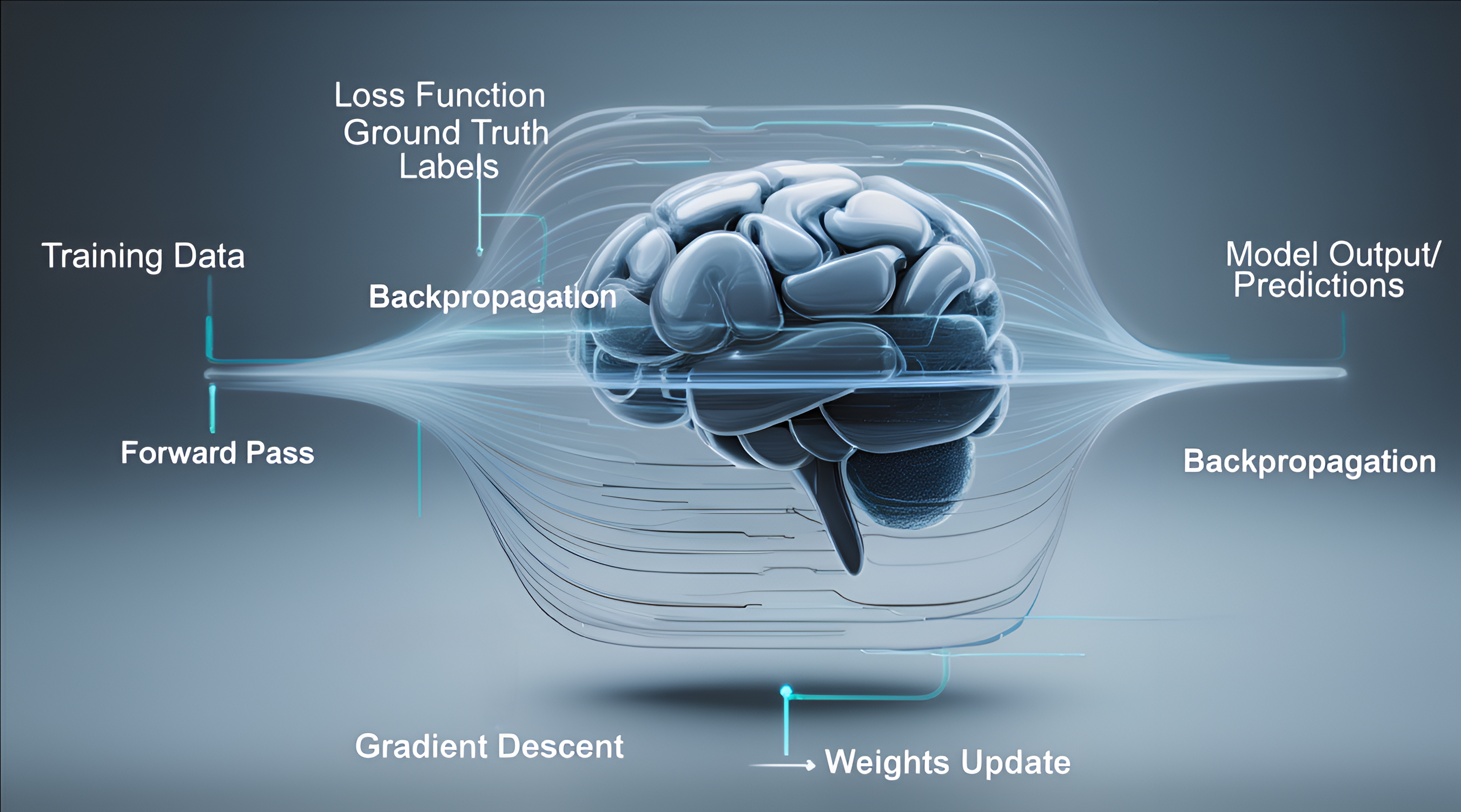
How Neural Networks Learn: Backpropagation
Learning happens in two phases:
-
Forward Pass
Input → hidden layers → output prediction -
Backward Pass (Backpropagation)
- Compare prediction to true label → calculate loss (error)
- Use gradient descent to adjust weights & biases to reduce loss
- Propagate error backward through layers → update each weight slightly
Repeat thousands/millions of times (epochs) on lots of data → the network gradually "learns" useful patterns.
Key ingredients for success:
- Lots of labeled data
- Good loss function (e.g., cross-entropy for classification)
- Smart optimizer (Adam is still king in 2026)
- Enough compute (GPUs/TPUs)
Why Neural Networks Matter So Much in 2026
Neural networks have become indispensable because they excel at:
- Pattern recognition in messy, high-dimensional data (images, audio, text, video)
- Automatic feature learning — no need for manual feature engineering
- Scaling with data & compute — bigger models + more data = dramatically better performance
Real-world impact in 2026:
| Domain | Neural Network Breakthroughs (2025–2026) | Everyday Examples |
|---|---|---|
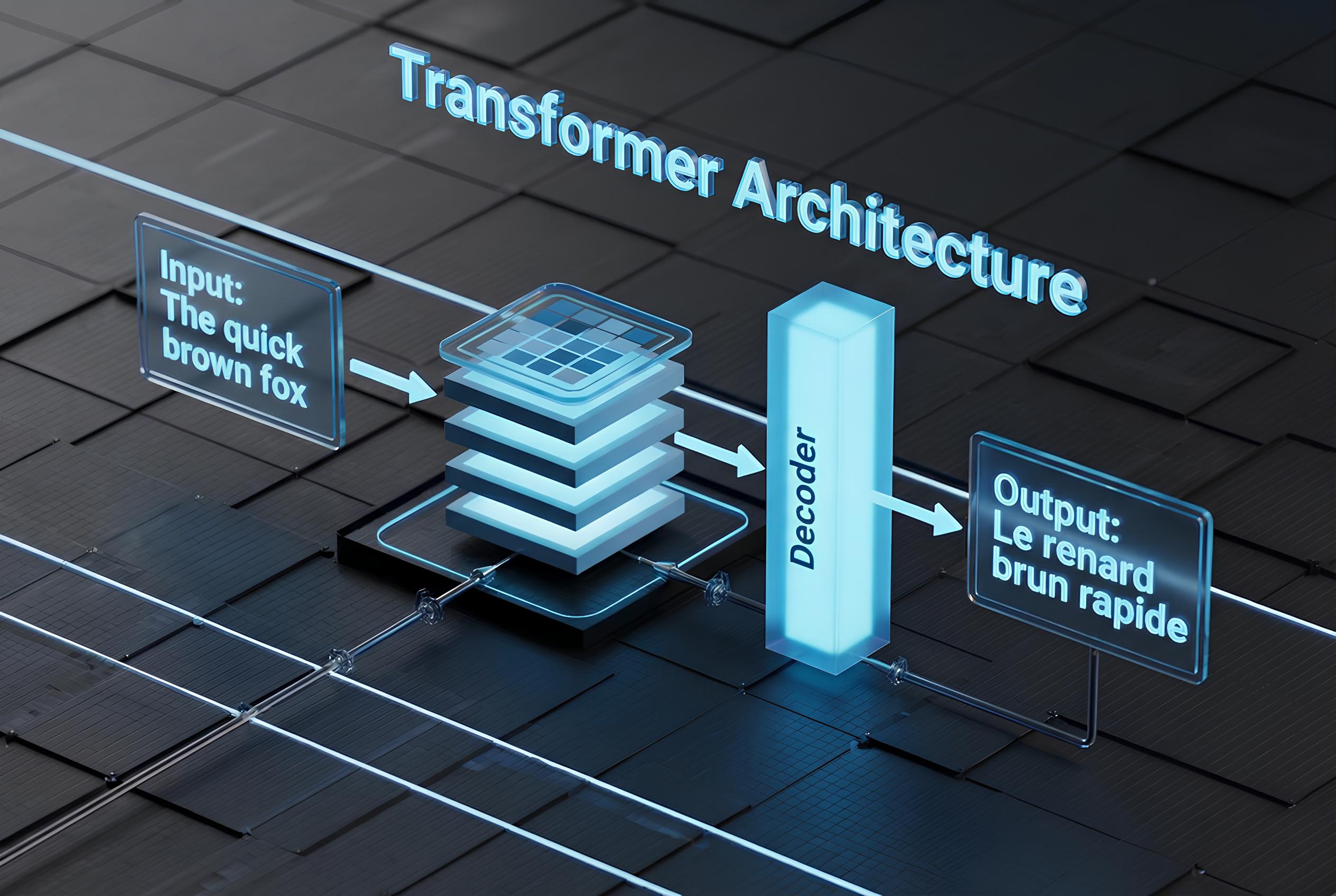
| Natural Language | Transformers (GPT, Llama, Grok families) | Chatbots, translation, content generation |
| Computer Vision | Diffusion models, vision transformers (ViT) | Object detection, medical imaging, AR/VR |
| Healthcare | CNNs + attention for diagnostics | Early cancer detection, drug discovery |
| Finance | LSTMs/Transformers for time-series | Fraud detection, algorithmic trading |
| Autonomous Systems | End-to-end neural control | Self-driving cars, drone navigation |
| Creative AI | Stable Diffusion, DALL·E 3/4, music models | AI art, music composition, video synthesis |
In Lagos and across Africa, neural networks already power:
- Mobile money fraud detection
- Agricultural yield prediction from satellite/drone imagery
- Local language translation & voice assistants
- Traffic & crowd analysis for smart cities
Quick Summary: Why Neural Networks Changed Everything
- They learn from examples instead of following rigid rules
- They scale incredibly well with data and compute
- They handle complex, real-world data (images, speech, text) better than anything before
- They are the foundation of modern AI — from LLMs to autonomous everything
Neural networks aren't magic — they're powerful function approximators trained with math and massive data. But their ability to discover hidden patterns has made them the most important tool in AI today.
Ready to go deeper? Next steps usually include:
- Building your first network (e.g., in PyTorch or TensorFlow/Keras)
- Understanding CNNs (for images) and Transformers (for text)
- Exploring hyperparameters and training tricks
References
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. (Still the bible)
- "Neural Networks and Deep Learning" by Michael Nielsen (free online book)
- 3Blue1Brown — "Neural Networks" YouTube series (visual masterpiece)
- IBM & AWS beginner guides on neural networks (updated 2025/2026 editions)
Recommended Insights
Continue your journey